When developing BI solutions one of the things we constantly struggle with is how to create the best data models. Often enough, a Data Warehouse will start performing slower and slower over time, to the point of smelling a faint burning smell from the server area. Most companies will as a result build a new shinier Data Warehouse that is going to get rid of all the previous problems and is going to be one hundred percent compatible with old solutions.
These projects often lead to failures, finger pointing, “I told you so” and a nice elaborate “lessons learned” document that puts the blame to “act of god” and is ignored by everyone.
While we can talk for long periods about the proper project management (and trust me we will), let’s focus on the basis of these problems first. The Data Model itself.
Inmon’s approach
Most traditional projects start with a structured approach of first analyzing, then designing and then executing. Inmon’s approach naturally follows from this way of working. In Inmon’s way of data modeling (let’s call it the Inmon model or IM from now on) we try to model the data in as much of the same way as the business is structured. We try to follow departments and their closest colleagues, all leading up to a data model that resembles on organogram.
This works great if we’re looking at a small to medium sized company!
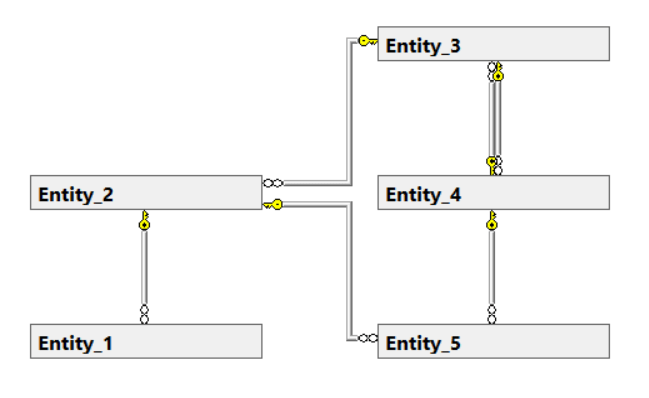
Not so great though when the company and thus the data model starts to grow…
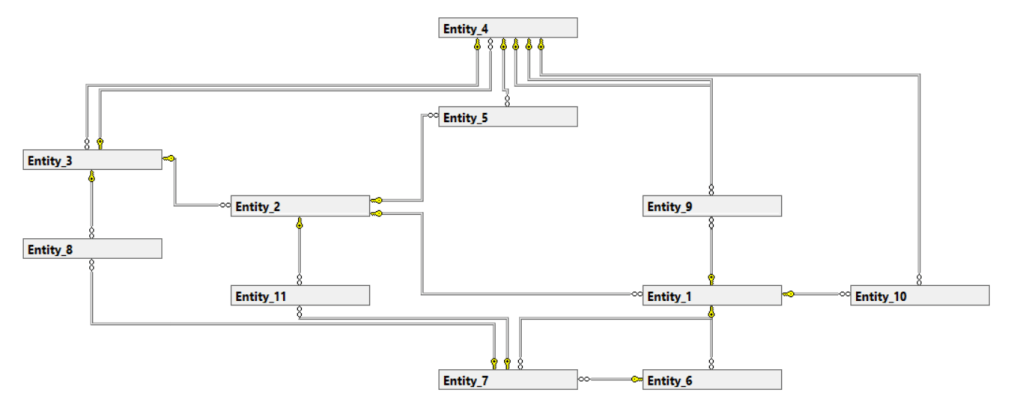
So let’s summarize the benefits of this way of modeling:
- Easier for business users because model resembles the business
- Integral solution, so only one version of “the truth”
- Relatively efficient, due to few joins needed for most users
And the obvious down sides:
- Requires a near prophetic vision during planning to make it future viable
- Every change made is highly impactful, potentially even impossible
- Difference between IT application model and IM means large amount of translation
Kimball’s approach
Fortunately, there are other ways of modeling your data, for example using the approach Kimball proposed. Kimball proposed what we now call the “Dimensional Model” (I’m going to call it DM). In this model we have a much smaller emphasis on pre planning and try to make the model as compact as possible.
The most common of applying the DM is by implementing a Star Schema. This means that you have one large “Fact” Table in the middle of your data model, surrounded by a multitude of “Dimension” Tables. The dimension tables are the easiest, since they are literally the dimensions to your data. This means the tables can contain date ranges (day week month, or even time), but also things like product categories, price lists and even product colour descriptions.
The fact table consists of a huge number of rows that all use the information from the dimensions to describe an entity of data. For example, we might look at a bicycle shop having bike sales in their Star Schema. The fact table links to the “product” table to get the right colour, the “data” table for the sales date, etc. Lastly it often adds a few extra columns to it such as a unique ID or some aggregations.
This is the shortest version of it, though very likely I’ll come back to a deeper dive at a later date.
Let’s look at a neat example of what a good functioning Star Schema could look like.
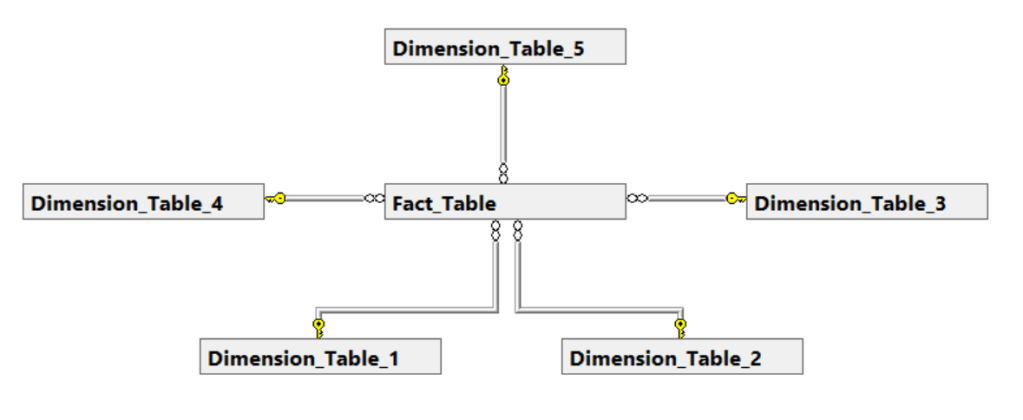
Even in the case of growing business requirements the Star Schema can often grow with it!
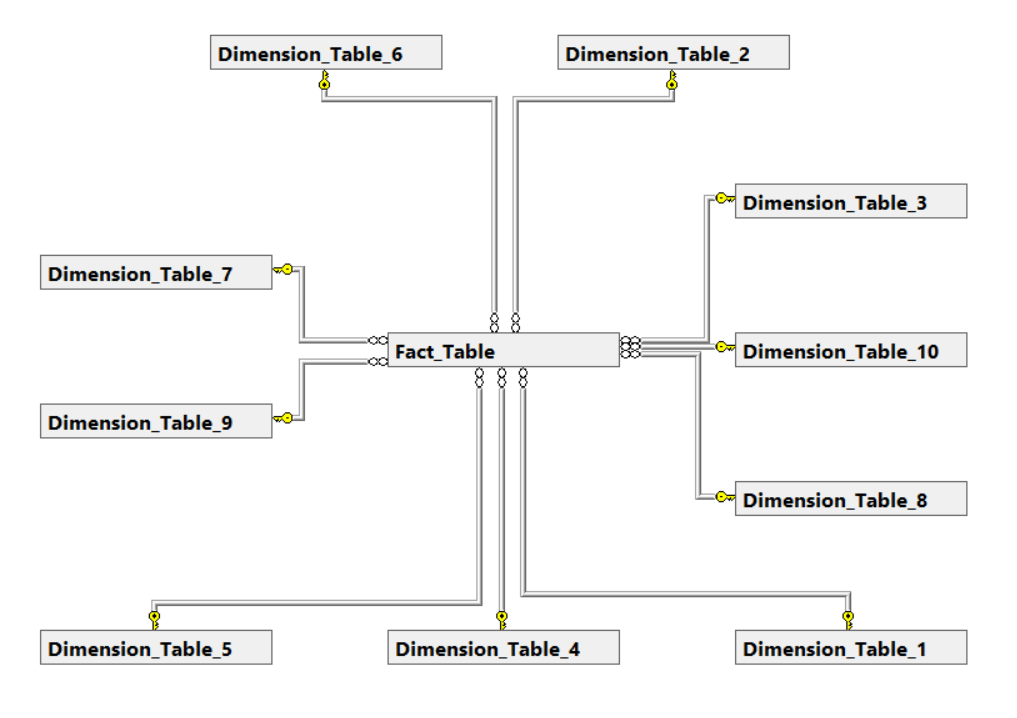
But not too much…
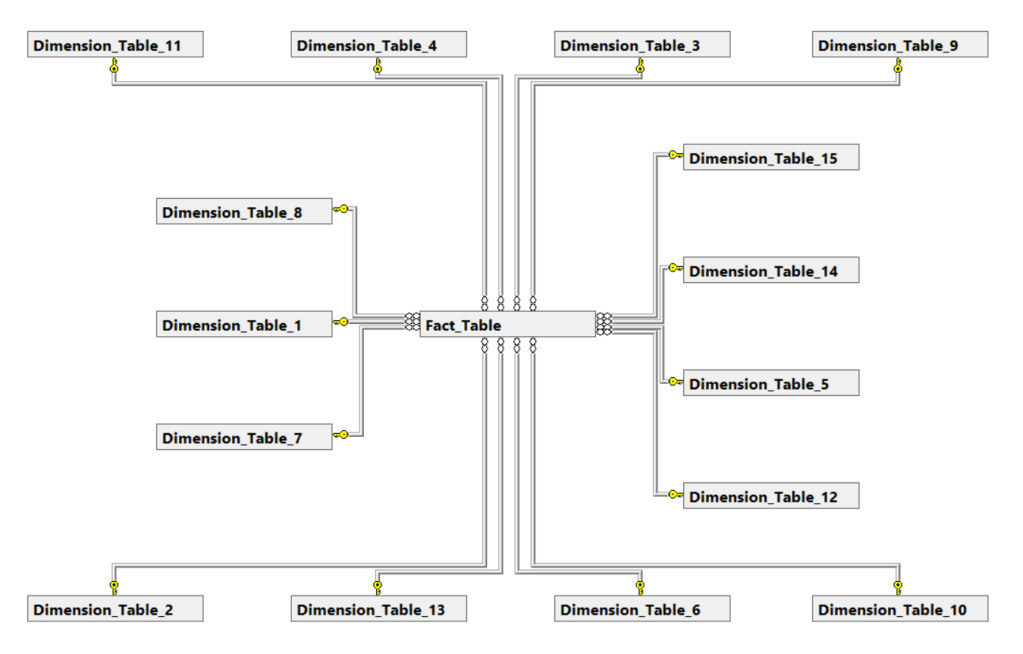
To combat this rapid growth, we can do something that we call “Snowflaking” which means that we take some of the dimensions that are related and link them to each other. This violates some of the major principles of the Star Schema (about which some people can be very passionate), but it can sometimes be a pragmatic solution.
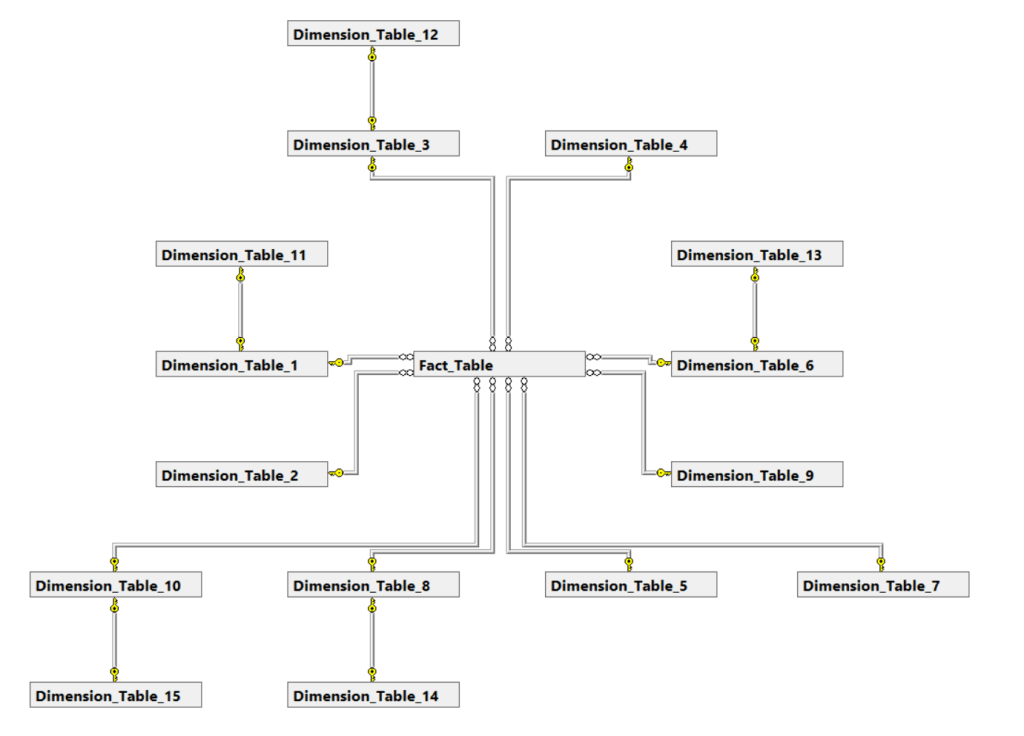
But even a snowflake has its limits…

Another way that people have tried to combat these growth issues, is by supplying multiple parallel Star Schema’s. This way every department has their own efficient Data Solution, with their own department specific requirements and adjustments. This works great, until John from accounting and Katie from marketing realize that their respective star schema’s produce different numbers due to all these different business rules.
So, let’s wrap this up again by starting with the benefits:
- Very limited design phase and very early first deliveries
- Easy to add to and very easy to change
- Very efficient due to the lack of multiple table connection paths
And what could possibly lead to some issues:
- Very difficult to scale from a certain point onward
- Multiple Models are advised, which removes the one version of “the truth”
- Model doesn’t enforce staying in line with business organization
Linsted’s approach
Fairly new to the block is Dan Linsted with his Data Vault modeling. While maybe the youngest of the bunch, Data Vault modeling tries to solve some of the problems that the other ways of modeling have and is actually quite good at some of the things!
The Data Vault (or DV from now on) has some similarities with IM, but tries to approach things a bit more agile just like DM. In a DV we have 3 kinds of tables, namely the Hub Sat and Link tables. A Hub is the most basic data of a business process concept, by design only containing a business key and some technical columns. Think of a table named Customers with only a customer id, or a table named Orders with only an Order key.
Now the Link tables are what makes this model work. The link tables (surprise surprise) provide the links between the different tables and only contain this relationship information. The thing that makes the DV so different than the IM however is that a relationship only goes through one path and often follows a natural department independent flow. For example, the Customer table is linked to the Orders table, which is linked to the Products table, which is linked to the Components table. This means I can’t be smart and link Components back to the Customer for a nice and easy shortcut!
Lastly the Satellites are what provides all the detail information and are linked to the Hub table. Think of a table with the specifications of the product, or the shipping details of an order. There is no limit to how many Satellites we can add to a Hub, however sometimes it can be easier to have 4 tables with 10 columns of relevant information than 8 tables with 5.
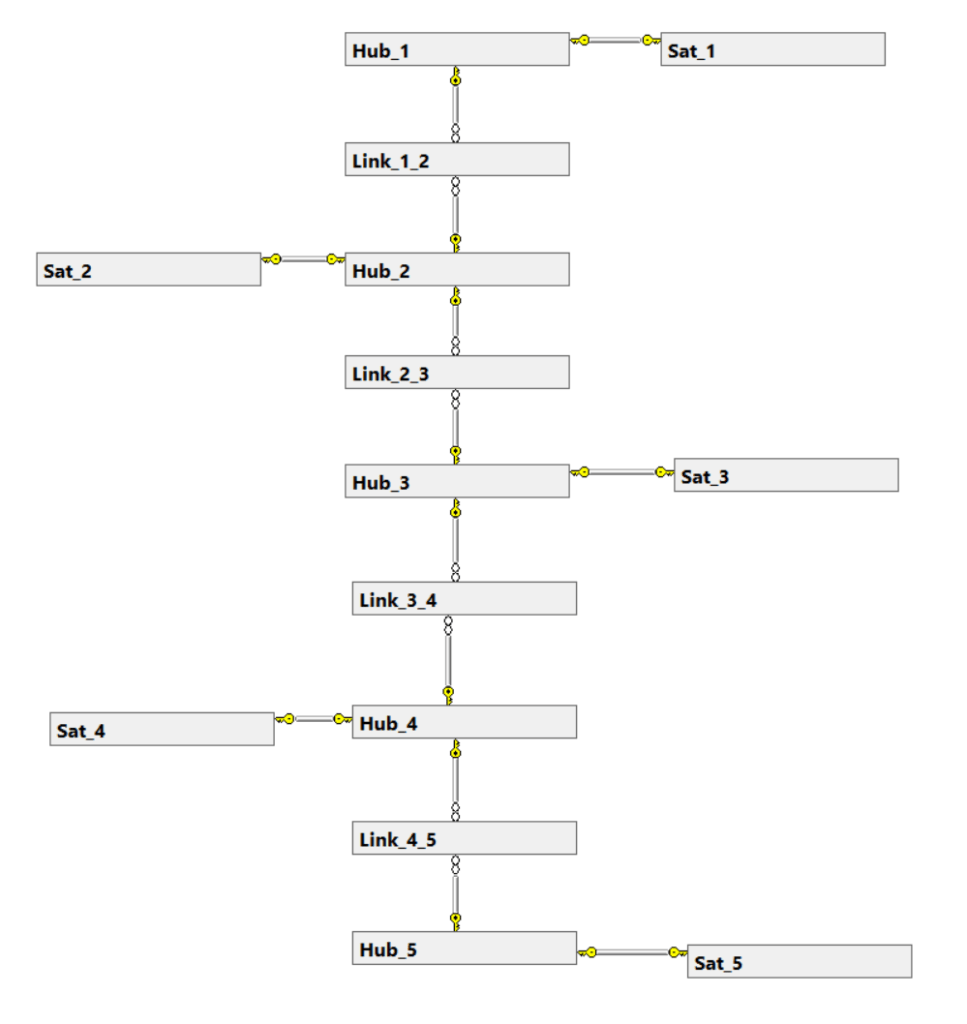
A small and simple version of a DV could look something like this.
There is no reason to think small though!
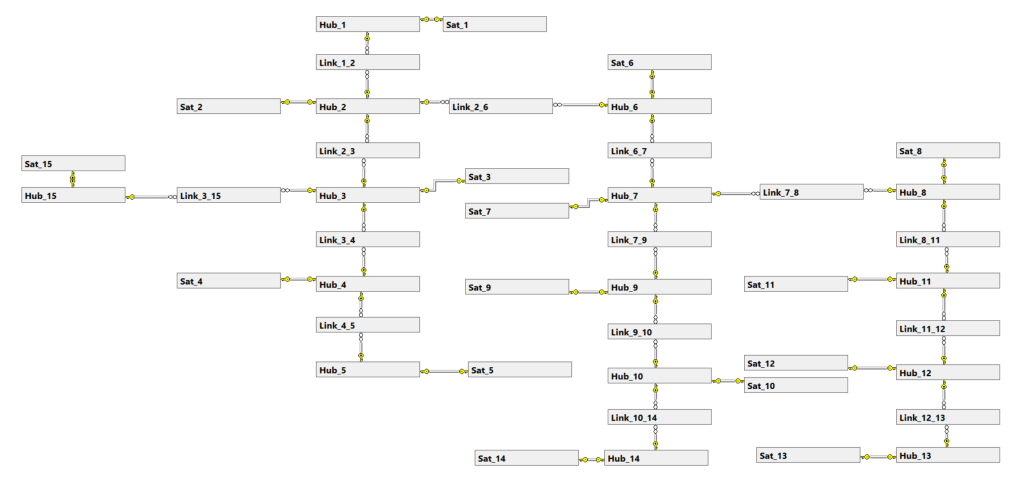
Without getting too technical though, this one possible table join path leads to some performance difficulties.
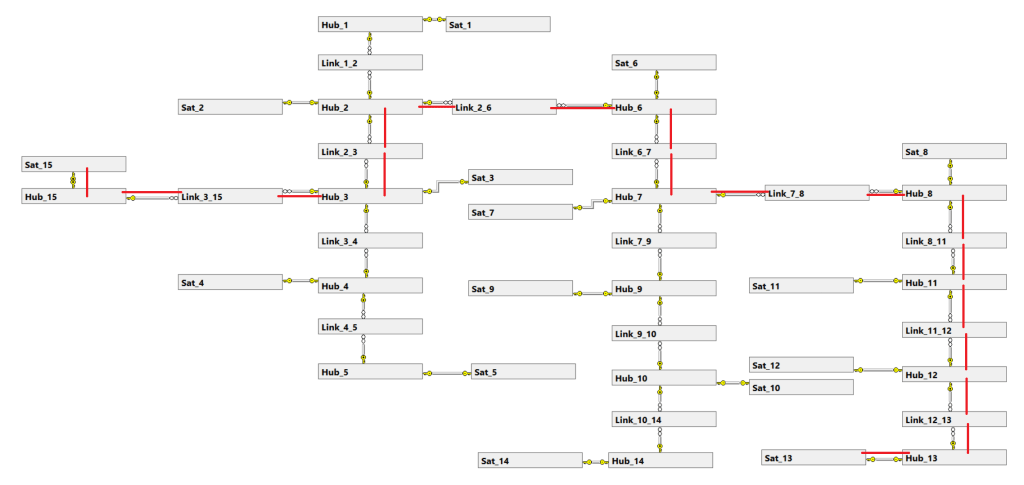
So what is the positive side of this way of working:
- Integral solution, so only one version of “the truth”
- Easy to understand by following business processes rather than organization
- Works with all sizes and easy to adjust along the way
Then why isn’t this the holy grail:
- Getting your data requires very long paths, making queries slow and expensive
- Can’t easily pick a subset of the model
- Requires remodeling when business processes change
Conclusion time!
If your business is relatively small and it doesn’t change all that much over the years, you can easily go for Inman’s approach. If you just need some cheap and easy data solution and you’re ok with different users having slightly different data, you can trust in the Kimball Model. Lastly if your company is changing and want to work together with the business in managing the data, you can trust in Linsted’s solution.
Me? I like the Data Vault. I like it that I can communicate with my non-data colleagues about my work, without needing to dumb things down. I like it that if I explain some basic querying, most business users can use the solution in its earliest phase. I’m okay spending some more to make everything run quicker and giving my non tech colleagues the tools to help the Data Warehouse development makes me save a bunch on hiring specialized consultants!

This is the most concise summary I’ve seen of the three approaches. Like your pro/con way of looking at each of them, as there truly are pros and cons to each. As you conclude, one needs to choose what is most appropriate for the environment they are in.
LikeLiked by 1 person
Thank you so much for your wonderful feedback! Glad you liked it, and I’ll try to make my following posts as concise/practical as this one! Hope you like the next ones as well (and deffo let me know if there are subjects you’d be interested in for a similar approach).
LikeLike
I’d really like to see a “real” example of DV, that is, an example with typical table names for a customer order system. It is new to me and I don’t really get it.
LikeLiked by 1 person
Good point! I made a detailed explanation at work, but that’s a chore to read 6500 words and counting. After the next blog I’ll detail data Vault OK?
LikeLike
What I like for the DV is that it represent the business concepts and the fact that the loading can be templated (beside all the other goodies that come with it) – and even new to a given business a developer can quickly be productive.
If I have the resources I would go with a DV and a Kimball styled DW for curated/cleaned data and performance.
LikeLike
Thanks for the reply and completely agree with you. Would be interested in learning more about how you do the templating!
LikeLike
Great article. The data vault looked a bit like a graph database, is it?
LikeLike
From what I know about Graph Databases it somewhat tries to do the same thing. I’ll start writing a blog explaining the Data Vault in more detail soon!
LikeLike
Excellent blog. As you rightly mentioned, no model is a perfect fit. Which approach to use depends no only upon the business case, and size, but also the speed at which business is growing. I personally like IM approach, however.
What do you think about using “Conforming Dimensions” in Kimball’s Star Schema model to get a single version of the truth?
LikeLike
Thank you for your positive words! There are many discussions between the IM model versus the DV so I will dive deeper into this subject.
When it comes to Conformed Dimensions it’s a pragmatic question again. Yes, it can work to provide a single version of the truth, but if you have 10-15 Star Schema Models all having multiple Conformed Dimensions it gets quite complex. Also keep in mind that multiple Star Schema Models might have different business rules behind this, and it gets more and more complex.
I am quite charmed by having a DV as the single version of the truth and having multiple Star Schema’s over this to connect to the reporting layer. By doing this you can have different business rules per Star Schema, and you can redirect your users to the DV for their “Single version of the truth” requirements.
Thanks for your enthusiasm! Hope you can give some comments on the next blog about DV modeling as well so I can learn more from your experience!
LikeLike
Excellent article. I have always used Kimball approach. I have never heard about Data Vault before. I would like to see an example of how to combine DV and a Kimball as GEORGI GEORGIEV mentioned.
LikeLike
Will do! Happy you’re positive! I might have an article on ML in Power Bi up first, but just follow me on twitter to get notified when the DV article goes up!
LikeLike