BI consultants have a large toolset available to best visualize and show the potential of data. One tool that is rarely used though is statistics. While I’m not a statistician by any stretch of the imagination, I’m going to attempt to explain in this blog how can get better insights in our data using basic statistical modeling.
We can do a lot of things with statistical modeling, so we should try to narrow it down to something that’s easy and valuable. For example, if we want to improve a metric such as revenue or profit margin, we need to be able to identify which factors have the highest impact. Let’s take the following table as our dataset for this exercise.
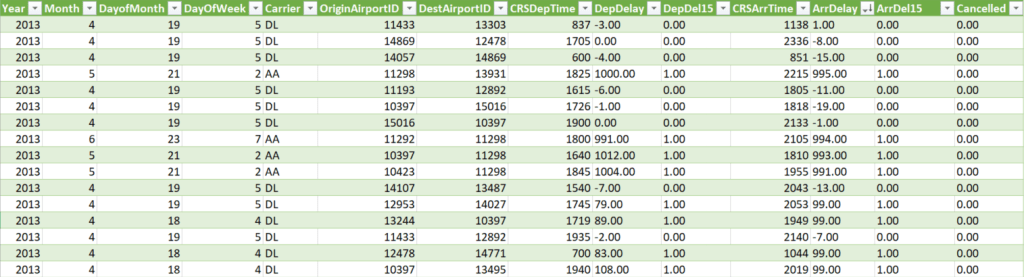
This is a standard dataset sample supplied by Microsoft describing airplane delays. For this exercise let’s make it our goal to determine what factors impact the delay of airplanes. We import this dataset into a local Database, and then we start our project!
Analysis
Let’s start by removing redundant columns. DepDel15 and ArrDel15 describe respectively the departure delays and the arrival delays to an extent, and as such we remove them from our selection. Since we want to find a general model for what determines delays we have no use for the individual airport ID’s, so we scrap those from our model as well. This leaves us with the following dataset.
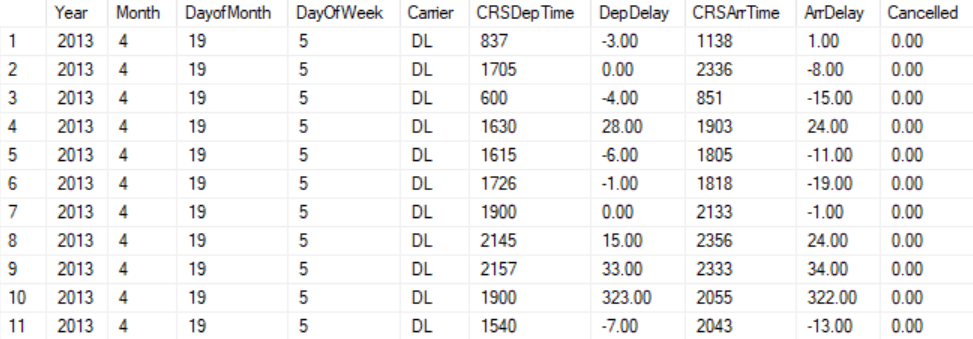
We can immediately see that we glossed over an obvious column. If a flight is cancelled there is not going to be a departure and arrival time, so we need to filter out all the flights that have been cancelled, after which we can safely remove the “Cancelled” column. Also, this dataset only contains data for 2013 so we don’t have to include this column either.
Now we have to start making decisions. We talked about looking for the factors that determine delay, however we have not stated yet which delay. Are we talking about the delay on departure or the delay on arrival? Our main purpose of flying is arriving at another destination, so my objective is the column “ArrDelay” as the measure we want to investigate.
One rule of statistics is that we want to get rid of variables that are too much correlated with each other from a logical perspective. Departure delays and arrival delays can only vary so much, since the bulk of the time is spent in the air. If we would include our departure delay in our model our conclusion would very likely be:
“the biggest determinant for arriving on time is leaving on time”
While this works great as an Instagram post, this does not provide us with new innovative insights (much like Instagram posts). For this reason, our model becomes more valuable if we remove the “DepDelay” column as well.
Let’s look at departure and arrival times. Our dataset is very limited in that we have no clue what our original flight times are or whether a flight is intercontinental. Since we’re just making a mockup we can look over this and purely look at the departure and arrival time since different times of the day could be susceptible to different delays
Lastly let’s look at the carrier. Since you can’t calculate based on string values, we need to find a way to turn these strings into numeric values. Thankfully there is a very easy way to do this, namely dummy variables!
What we do when we create dummy variables, is make a column for every possible string value we want to check against a baseline. When we create a dummy variable, we’re just asking the basic binary question whether the row belongs to the airline company of that column which can obviously only result in a 1 or a 0.
Let’s say in this case we take every Carrier that had more than 100.000 flights in the year 2013 and compare them to the baseline of airlines that were below 100.000. By checking the number of flights per airline we get this list of applicable airlines:
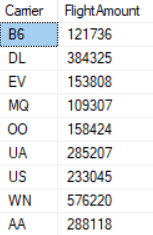
All these steps result in the following dataset:
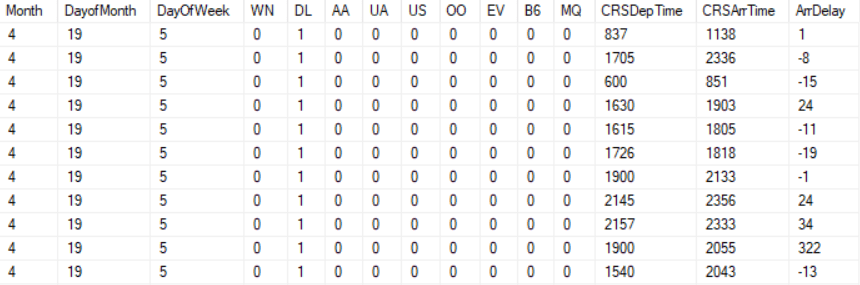
Either export these results to a CSV format or upload them to a cloud accessible SQL Database. Make sure that in the case of CSV output you make sure it is using a “,” as a separator and not “;”, which can easily be changed by opening the file in notepad. When using a SQL database, make sure all your variables are of the integer data type.
Implementation
Let’s start our analysis by logging into Azure ML Studio (AMLS). We first need to upload our current data to AMLS or link our online storage solution to these services. If the data needs to be uploaded go to “Datasets” -> “New” -> “Local file” and for linking servers just keep on reading.
In either case you will now go to “Experiments” -> “New” -> “Blank Experiment”. We’re greeted by a fancy looking user interface in which we will either click “Saved Datasets” -> “My Datasets” and drag [Saved Dataset Name] to the main screen.
If you chose to upload your dataset to a dataset server, the only thing you’ll need to do is go to “Experiments” -> “New” -> “Blank Experiment”, click “Data Input and Output” and drag “Import Data” to the screen to configure your preferred database.
From this moment onward, our process will be the same for both choices. We split our dataset using “Data Transformation” -> “Sample and Split” -> “Split Data” so that we randomly split our data between data we use to create our model with and data we use to apply our final model to. For now, we change 0.5 into 0.7 to have a bit more training data. After this we click “Machine Learning” -> “Initialize Model” -> “Regression” -> “Linear Regression” to tell AMLS that we’re trying to perform a linear regression analysis and leave the configuration as it is right now.
We go to “Machine Learning” -> “Train” -> “Train Model” to explicitly tell AMLS to create our model for us, after which we add “Machine Learning” -> “Score” -> “Score Model” and “Machine Learning” -> “Evaluate” -> “Evaluate Model”. After this we’re going to connect our steps so that we get the following image:
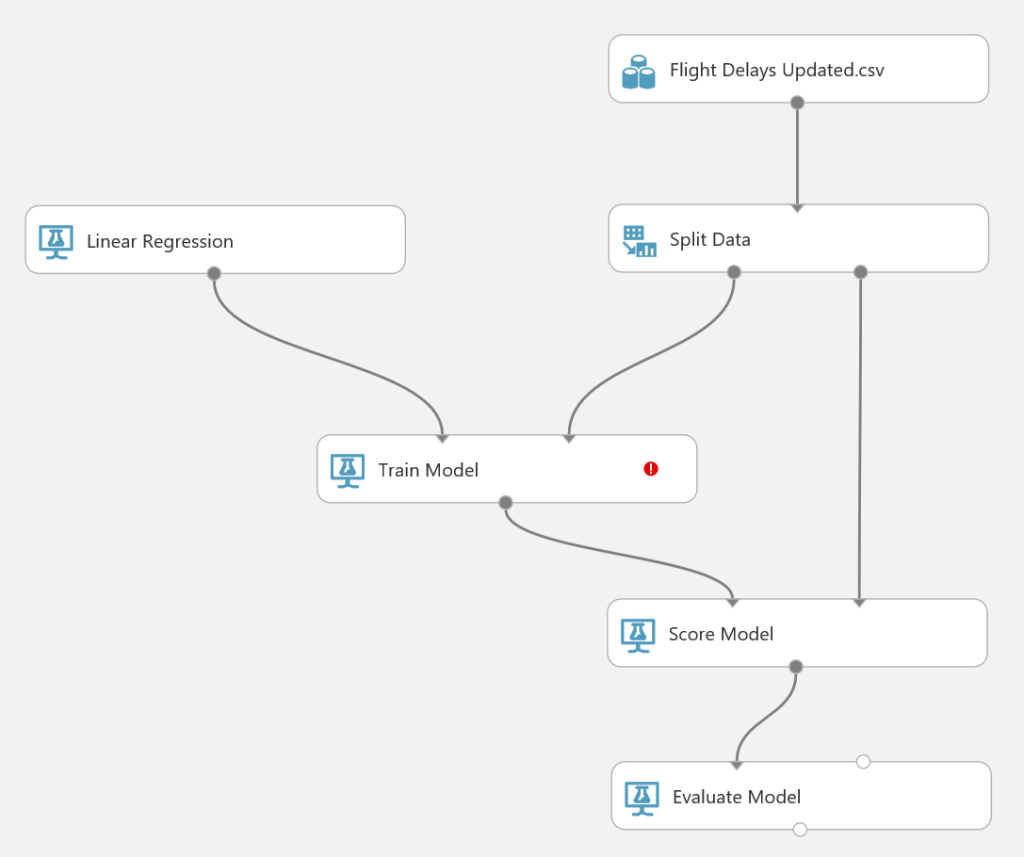
The only thing remaining is clicking “Train Model” and then clicking “Launch column selector” to define which variable we’re trying to investigate, which in our case is the column “ArrDelay”. A popup might not show, so just typing this name and pressing Enter should be sufficient.
We’re now ready to run our model! Let’s start by pressing the “Run” button on the bottom. Once we’ve done that and all the green checkmarks appear, it’s time to check if this model is valuable. Right click “Evaluate Model” -> “Evaluation Results” -> “Visualize” and see what the coefficient of determination is:
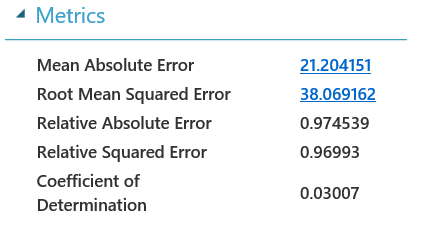
This number states that 3% percent of variance in the dataset can be explained by the variables in the model. Given that a Coefficient of Determination of 1 would mean a perfectly fitting model we have quite some way to go. Luckily, when clicking right on “Train Model” -> “Trained Model” -> “Visualize” we can get an idea of what we can do to improve the model.
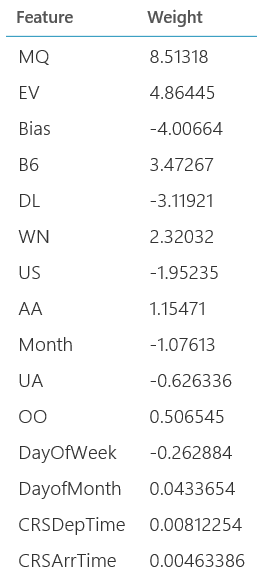
Some of these objects don’t make much sense when we think about what is happening. This model is now saying that the higher the month number, the lower the delay is, but this doesn’t consider that different seasons will have different levels of traffic. If we would look on a month by month basis we could get a better estimation.
The same counts for departure and arrival times and days of the week. Values like dates can be useful to check out separately so for every value minus one we create a column. This means for “Month” we will compare everything to April (since our data reaches form April to October), for “Day of the week” we will compare everything to Sunday.
For “Departure Time” and “Arrival Time” we should be a bit more general though. We can easily create buckets of “Morning”, “Afternoon”, “Evening” and “Night” going from 06:00-12:00, 12:00-18:00, 18:00-00:00 and 00:00 to 06:00 where we take our “Night” bucket as our baseline. For the [Day of the Month] we can make an arbitrary number of buckets, but for now let’s stick to “Beginning of the Month” from the 1st until the 10th, “Middle of the Month” from the 11th until the 20th, and “End of the Month” for everything from the 21st and later which will be our baseline.
What we’ve just done is we’ve gotten rid of all our potentially nonlinear relationships, which is a key objective in doing linear regression analysis!
Let’s see what happens when we process our newly made dataset:
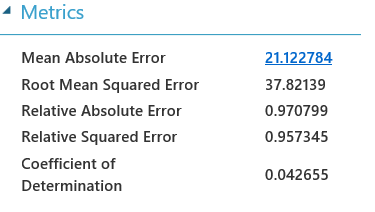
It’s better but it’s not exactly what we can call good. That’s all okay though! This just means that the variables we have used in the model are just very bad predictors of potential delays, and we can’t revolutionize the aviation industry with our ground-breaking model. Very unfortunate, but within expectation.
Let’s just for one moment imagine that the coefficient of Determination was around 0.8, which would mean that our model could help explain 80% of the variation in the data. In that case it would be very interesting what kind of variables have the highest impact on delays.

We get a nice top view of what kind of variables would in this case be a good determinant. It’s important to realize how to interpret these results not being a statistician though. Based on experience, if we want to decrease our delays we should look at what we can do to improve the performance during the evenings, and we can see specific airlines do significantly worse than others. The Thursday and Friday flights seem to most susceptible to delays, and the moment in the month seems to be relatively irrelevant.
Conclusion Time!
This was a crash course in how to apply statistic principles and easy to use tools to get more insight in your data. While the exercise that we did didn’t lead to a good model, we managed to get a model up and running and determined what variables were important if we did find a statistical relevance to our model.
We can do so much more with our data than just showing aggregates and some calculated measures. Lucky enough we now live in an age where we have drag and drop interfaces that make it super easy to use statistics to get more info on our data and help us set up focus areas for next periods.
If we want better models, it’s a good idea to get a data scientist/statistician involved. Until that moment though, with these kind of drag and drop interfaces we finally have some easy ways to get more out of our data!
